🧠 [AI] rating summary
🤔 Analysis Trace
🏷️ Tech/Dev | 信息密度:8 | 🆕 新颖度:7 判断: 一篇深入剖析AI智能体上下文工程核心策略的文章,内容扎实,提供了应对LLM性能瓶颈的实用技术思路。
🎯 核心信号 (The Signal)
- 一句话:Manus通过实施上下文缩减、卸载和隔离三大工程策略,有效管理LLM的上下文窗口,以构建更高效、可扩展且能适应模型进化的AI智能体。
- 关键要点或时间证据链条线:
- 问题识别:AI智能体在多工具调用和任务执行中,LLM上下文窗口会累积大量信息,导致性能下降(上下文腐烂)和成本增加。
- 上下文缩减:通过将旧的工具调用结果“压缩”为引用(如文件路径),并在必要时进行模式化摘要,来减少LLM上下文中的实际令牌数量。
- 上下文卸载:将完整的工具结果存储在虚拟机的本地文件系统中,并通过少数通用工具(如Bash、文件系统访问)在沙盒中执行大部分操作,而非将所有功能绑定为独立工具。
- 上下文隔离:利用子智能体处理离散任务,为每个子智能体提供独立的上下文窗口,并根据任务复杂度有选择地共享上下文(仅指令或完整上下文)。
- 适应模型进化:强调“痛苦的教训”(Bitter Lesson),建议构建无偏见的智能体框架,并通过跨不同模型强度的评估,确保框架不会限制未来模型的性能提升。
⚖️ 立场与倾向 (Stance & Bias)
- 作者意图:深度探讨 / 分享见解与实践
- 潜在偏见:文章基于Manus的实践经验,其策略虽具普适性,但可能侧重于特定工程权衡,对其他可能的上下文管理方法提及较少。
🌲 关键实体与作用 (Entities & Roles)
- Manus : 本文的核心案例,一个通用的消费级AI智能体,其上下文工程实践是文章讨论的主体。 ⇒ 正面
- Lance Martin : 文章作者,基于与Manus联合创始人兼CSO的研讨会内容,分享对上下文工程的见解。 ⇒ 中立
- Yichao “Peak” Ji : Manus的联合创始人兼CSO,在研讨会上分享了Manus的实践经验和思考。 ⇒ 中立
- Anthropic : LLM开发商,提供了智能体和上下文工程的定义,并被引用以说明类似的工程策略和挑战。 ⇒ 中立
- Karpathy : 知名AI研究员,被引用以明确“上下文工程”的定义,强调其重要性。 ⇒ 中立
- The Bitter Lesson : AI领域的一个重要思想,强调计算和通用方法的潜力,鼓励去除复杂的手工工程,对智能体框架设计有指导作用。 ⇒ 指导原则
- E2B : 提供云端虚拟机环境,Manus利用其为智能体提供沙盒环境。 ⇒ 正面
💡 启发性思考 (Heuristic Questions)
- 随着大型语言模型上下文窗口的持续扩展和长上下文能力的提升,未来“上下文工程”的重点会如何从管理大小转向管理质量和效率?
original content
Why Context Engineering
Earlier this week, I had a webinar with Manus co-founder and CSO Yichao “Peak” Ji. You can see the video here, my slides here, and Peak’s slides here. Below are my notes.
Anthropic defines agents as systems where LLMs direct their own processes and tool usage, maintaining control over how they accomplish tasks. In short, it’s an LLM calling tools in a loop.
Manus is one of the most popular general-purpose consumer agents. The typical Manus task uses 50 tool calls. Without context engineering, these tool call results would accumulate in the LLM context window. As the context window fills, many have observed that LLM performance degrades.
For example, Chroma has a great study on context rot and Anthropic has explained how growing context depletes an LLM’s attention budget. So, it’s important to carefully manage what goes into the LLM’s context window when building agents. Karpathy laid this out clearly:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step (in an agent’s trajectory)
上下文工程是精心掌握的艺术与科学,即在上下文窗口中填入恰好适合下一步(在智能体轨迹中)的必要信息
Context Engineering Approaches
Each Manus session uses a dedicated cloud-based virtual machine, giving the agent a virtual computer with a filesystem, tools to navigate it, and the ability to execute commands (e.g., provided utilities and standard shell commands) in that sandbox environment.
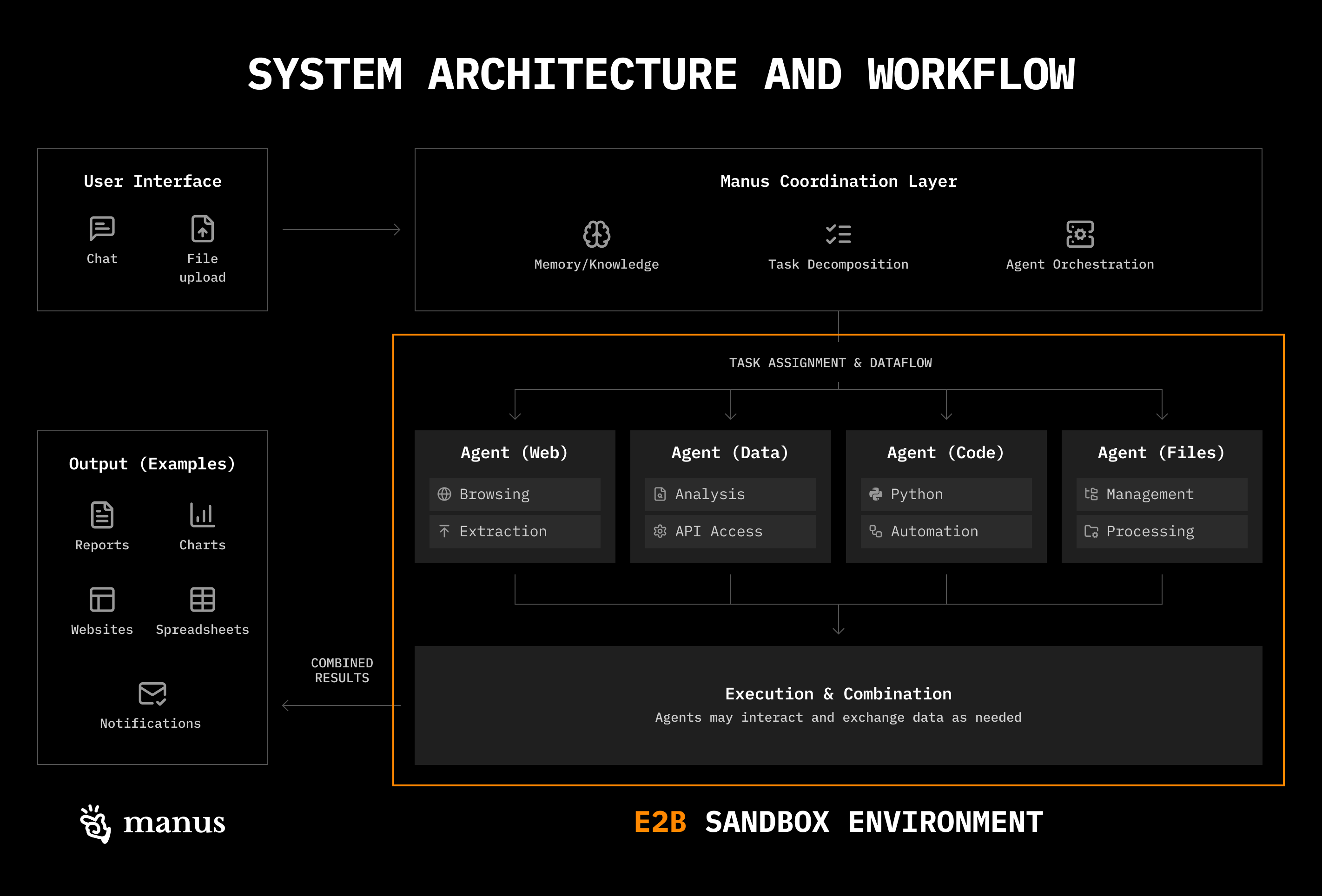
In this sandbox, Manus uses three primary strategies for context engineering, which align with approaches Anthropic covers here and I’ve seen in across many projects:
- Reduce Context
- Offload Context
- Isolate Context
Context Reduction
Tool calls in Manus have a “full” and “compact” representation. The full version contains the raw content from tool invocation (e.g., a complete search tool result), which is stored in the sandbox (e.g., filesystem). The compact version stores a reference to the full result (e.g., a file path).
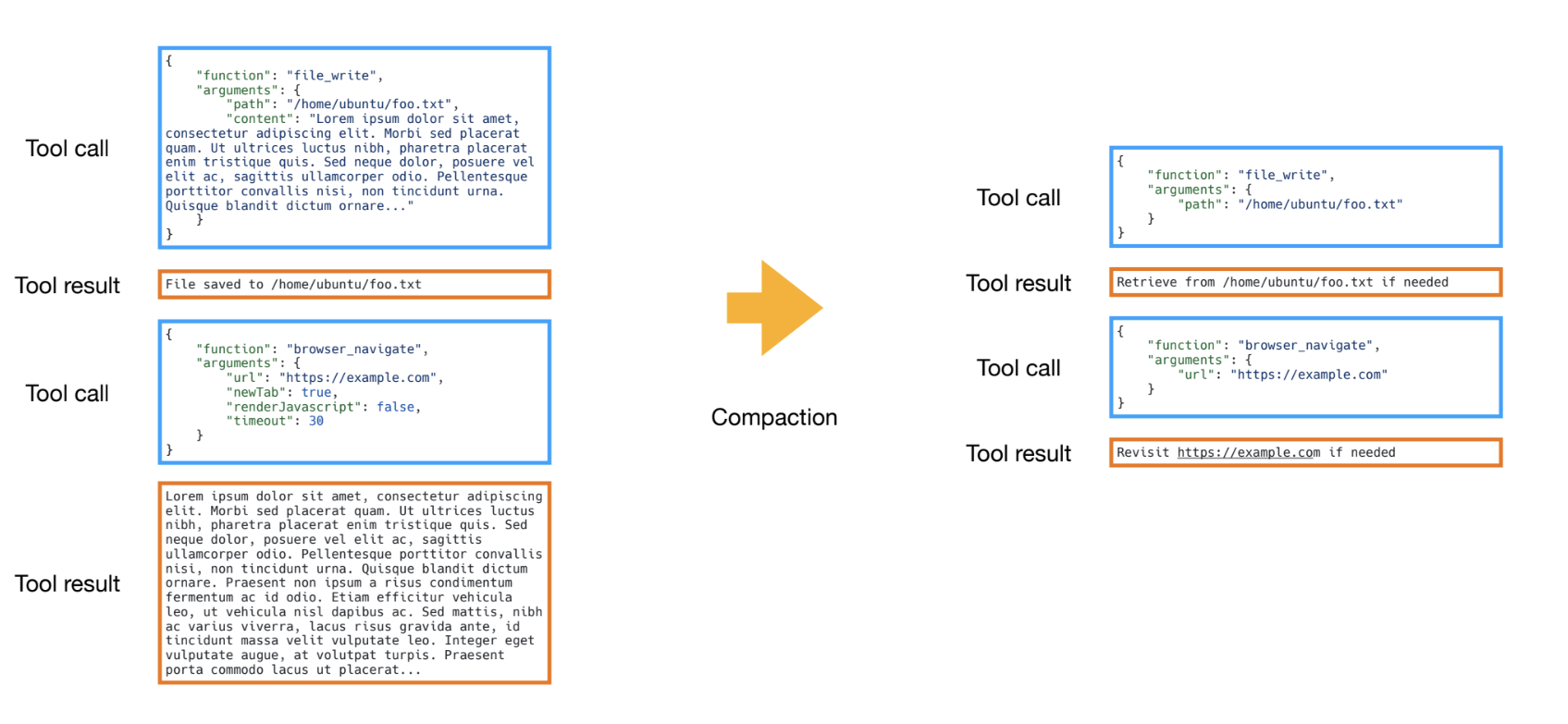
Manus applies compaction to older (“stale”) tool results. This just means swapping out the full tool result for the compact version. This allows the agent to still fetch the full result if ever needed, but saves tokens by removing “stale” results that the agent has already used to make decisions.
Newer tool results remain in full to guide the agent’s next decision. This seems to be a generally useful strategy for context reduction, and I notice that it’s similar to Anthropic’s context editing feature:
Context editing automatically clears stale tool calls and results from within the context window when approaching token limits. As your agent executes tasks and accumulates tool results, context editing removes stale content while preserving the conversation flow, effectively extending how long agents can run without manual intervention.
上下文编辑会在接近令牌限制时自动清除上下文窗口内的过期工具调用和结果。当您的代理执行任务并积累工具结果时,上下文编辑会移除过期内容,同时保持对话流程的连贯性,从而有效延长代理在无需手动干预的情况下运行的时间。
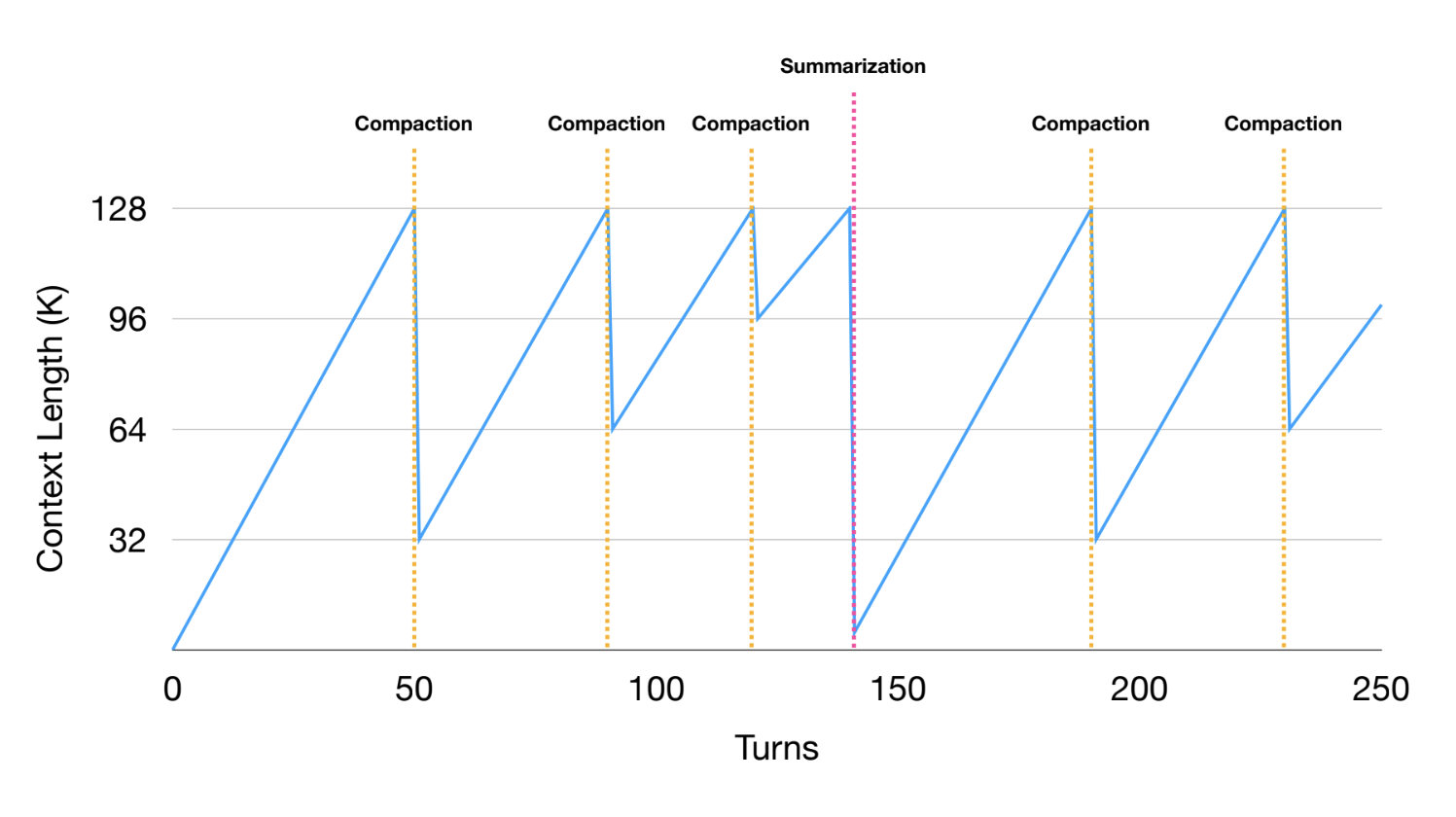
When compaction reaches diminishing returns (see figure below), Manus applies summarization to the trajectory. Summaries are generated using full tool results and Manus uses a schema to define the summary fields. This creates a consistent summary object for any agent trajectory.
Context Isolation
Manus takes a pragmatic approach to multi-agent, avoiding anthropomorphized divisions of labor. While humans organize by role (designer, engineer, project manager) due to cognitive limitations, LLMs don’t necessarily share these same constraints.
With this in mind, the primary goal of sub-agents in Manus is to isolate context. For example, if there’s a task to be done, Manus will assign that task to a sub-agent with its own context window.
Manus uses multi-agent with a planner that assigns tasks, a knowledge manager that reviews conversations and determines what should be saved in the filesystem, and an executor sub-agent that performs tasks assigned by the planner.
Manus initially used a todo.md for task planning, but found that roughly one-third of all actions were spent updating the todo list, wasting valuable tokens. They shifted to a dedicated planner agent that calls executor sub-agents to perform tasks.
In a recent podcast, Erik Schluntz (multi-agent research at Anthropic) mentioned that they similarly design multi-agent systems with a planner to assign tasks and use function calling as the communication protocol to initiate sub-agents. A central challenge raised by Erik as well as Walden Yan (Cognition) is context sharing between planner and sub-agents.
Manus addresses this in two ways. For simple tasks (e.g., a discrete task where the planner only needs the output of the sub-agent), the planner simply creates instructions and passes them to the sub-agent via the function call. This resembles Claude Code’s task tool.
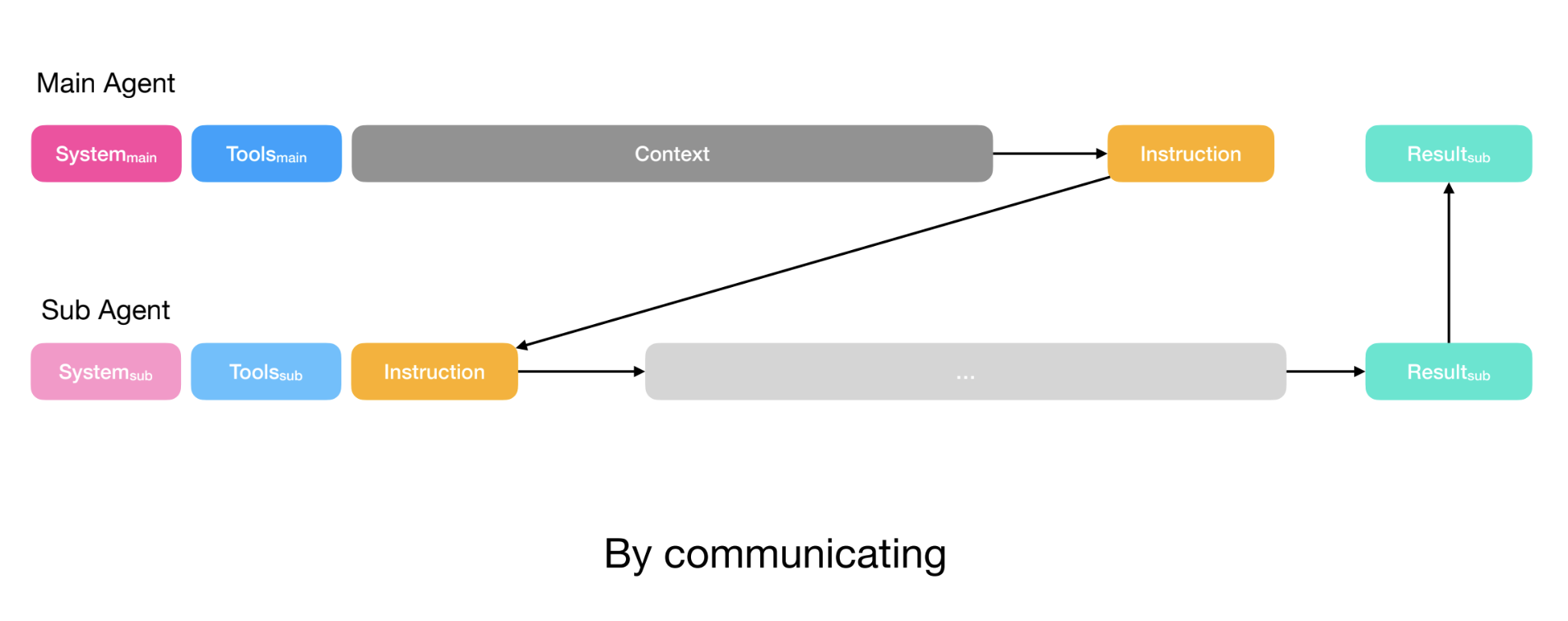
For more complex tasks (e.g., the sub-agent needs to write to files that the planner also uses), the planner shares its full context with the sub-agent. The sub-agent still has its own action space (tools) and instructions, but receives the full context that the planner also has access to.
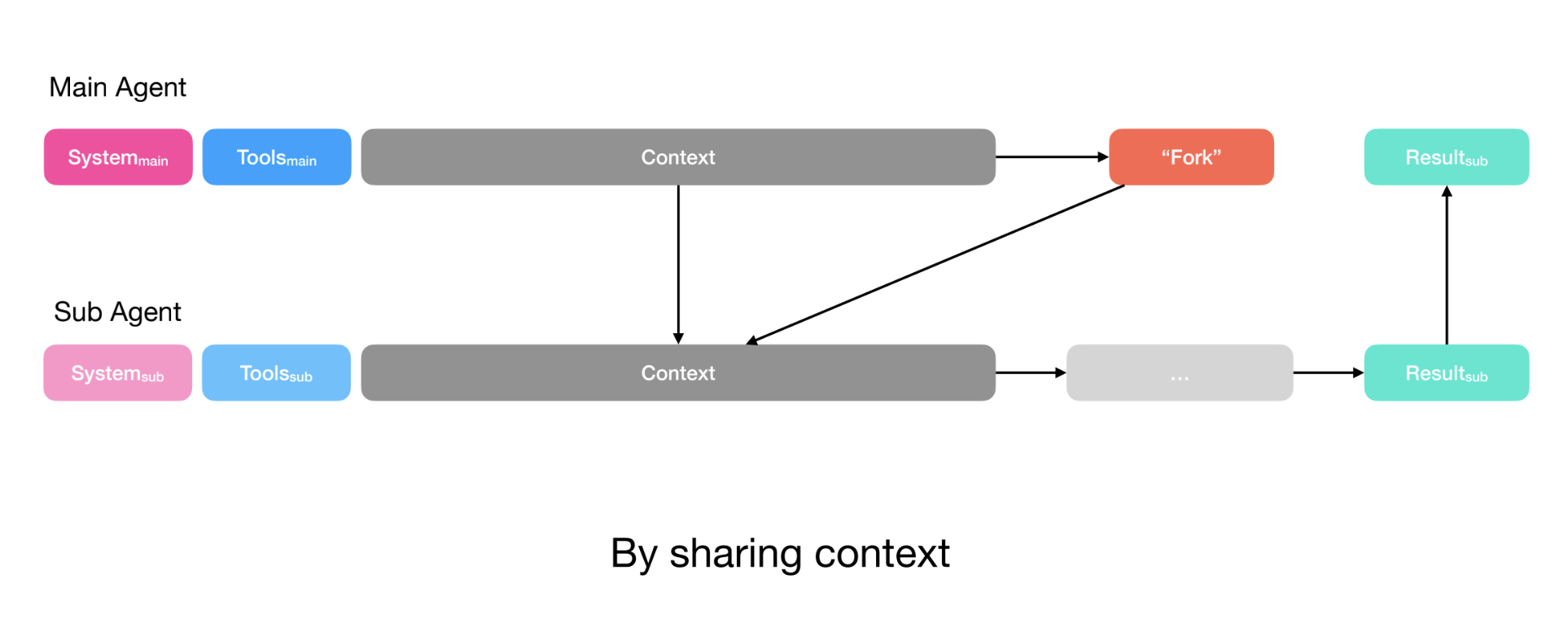
In both cases, the planner defines the sub-agent’s output schema. Sub-agents have a submit results tool to populate this schema before returning results to the planner and Manus uses constrained decoding to ensure output adheres to the defined schema.
Tools Definitions
We often want agents that can perform a wide range of actions. We can, of course, bind a large collection of tools to the LLM and provide detailed instructions on how to use all of them. But, tool descriptions use valuable tokens and many (often overlapping or ambiguous) tools can cause model confusion.
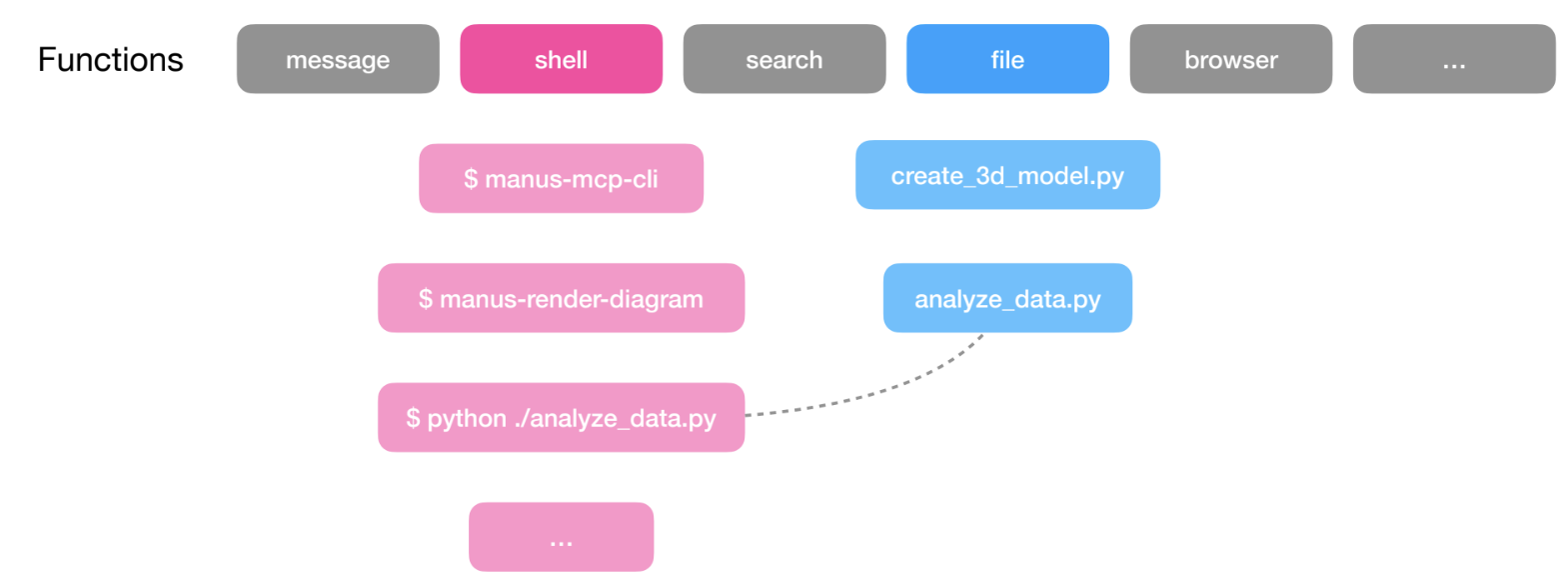
A trend I’m seeing is that agents use a small set of general tools that give the agent access to a computer. For example, with only a Bash tool and a few tools to access a filesystem, an agent can perform a wide range of actions!
Manus thinks about this as a layered action space with function/tool calling and its virtual computer sandbox. Peak mentioned that Manus uses a small set (< 20) of atomic functions; this includes things like a Bash tool, tools to manage the filesystem, and a code execution tool.
Rather than bloating the function calling layer, Manus offloads most actions to the sandbox layer. Manus can execute many utilities directly in the sandbox with its Bash tool and MCP tools are exposed through a CLI that the agent can also execute using the Bash tool.
Claude’s skills feature uses a similar idea: skills are stored in the filesystem, not as bound tools, and Claude only needs a few simple function calls (Bash, file system) to progressively discover and use them.
Progressive disclosure is the core design principle that makes Agent Skills flexible and scalable. Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix, skills let Claude load information only as needed … agents with a filesystem and code execution tools don’t need to read the entirety of a skill into their context window when working on a particular task.
Tool Results
Because Manus has access to a filesystem, it can also offload context (e.g., tool results). As explained above, this is central for context reduction; tool results are offloaded to the filesystem in order to produce the compact version and this is used to prune stale tokens from the agent’s context window. Similar to Claude Code, Manus uses basic utilities (e.g., glob and grep) to search the filesystem without the need for indexing (e.g., vectorstores).
Model Choice
Rather than committing to a single model, Manus uses task-level routing: it might use Claude for coding, Gemini for multi-modal tasks, or OpenAI for math and reasoning. Broadly, Manus’s approach to model selection is driven by cost considerations, with KV cache efficiency playing a central role.
Manus uses caching (e.g., for system instructions, older tool results, etc) to reduce both cost and latency across many agent turns. Peak mentioned that distributed KV cache infrastructure is challenging to implement with open source models, but is well-supported by frontier providers. This caching support can make frontier models cheaper for certain (agent) use-cases in practice.
Build with the Bitter Lesson in Mind
We closed the discussion talking about the Bitter Lesson. I’ve been interested in its implications for AI engineering. Boris Cherny (creator of Claude Code) mentioned that The Bitter Lesson influenced his decision to keep Claude Code unopinionated, making it easier to adapt to model improvements.
Building on constantly improving models means accepting constant change. Peak mentioned that Manus has been refactored five times since their launch in March!
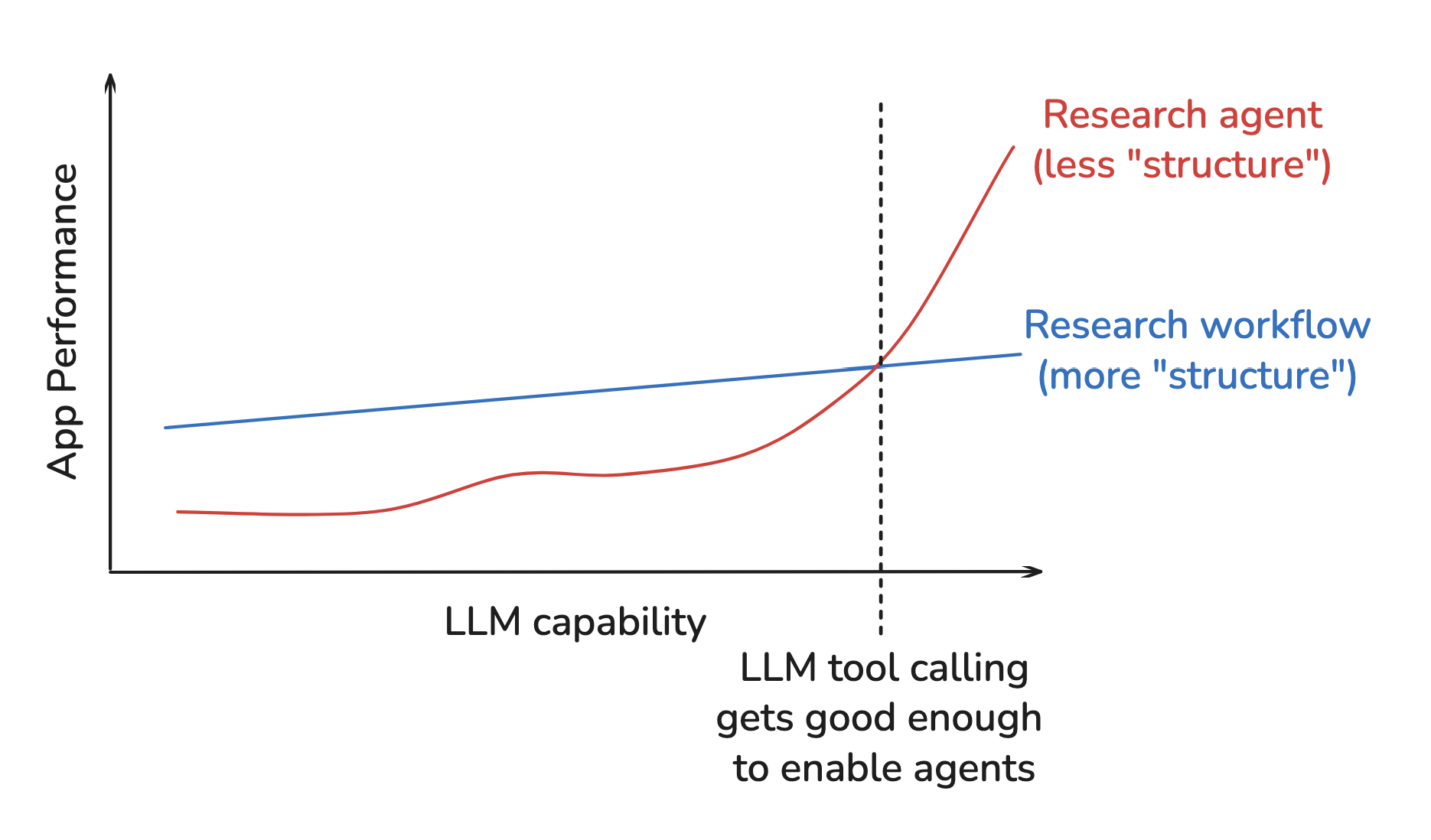
In addition, Peak warned that the agent’s harness can limit performance as models advance; this is exactly the challenge called out by the Bitter Lesson. We add structure to improve performance at a point in time, but this structure can limit performance as compute (models) grows.
To guard against this, Peak suggested running agent evaluations across varying model strengths. If performance doesn’t improve with stronger models, your harness may be hobbling the agent. This can help test whether your harness is “future proof”.
Hyung Won Chung’s (OpenAI/MSL) talk on this topic further emphasizes the need to consistently re-evaluate structure (e.g., your harness / assumptions) as models improve.
Add structures needed for the given level of compute and data available. Remove them later, because these shortcuts will bottleneck further improvement.
Conclusions
Giving agents access to a computer (e.g., filesystem, terminal, utilities) is a common pattern we see across many agents, including Manus. It enables a few context engineering strategies:
1. Offload Context
- Store tool results externally: Save full tool results to the filesystem (not in context) and access on demand with utilities like
globandgrep - Push actions to the sandbox: Use a small set of function calls (Bash, filesystem access) that can execute many utilities in the sandbox rather than binding every utility as a tool
2. Reduce Context
- Compact stale results: Replace older tool results with references (e.g., file paths) as context fills; keep recent results in full to guide the next decision
- Summarize when needed: Once compaction reaches diminishing returns, apply schema-based summarization to the full trajectory
3. Isolate Context
- Use sub-agents for discrete tasks: Assign tasks to sub-agents with their own context windows, primarily to isolate context (not to divide labor by role)
- Share context deliberately: Pass only instructions for simple tasks; pass full context (e.g., trajectory and shared filesystem) for complex tasks where sub-agents need more context
A final consideration is to ensure your harness is not limiting performance as models improve (e.g., be “Bitter Lesson-pilled”). Test across model strengths to verify this. Simple, unopinionated designs often adapt better to model improvements. Finally, don’t be afraid to re-build your agent as models improve (Manus refactored 5 times since March)!